The technology we have at our fingertips to connect people with information continues to grow. Chatbots and virtual assistants are one of the main portals for accessing knowledge as a consumer, an employee, a patient, and more. The most effective chatbots are enhanced with machine learning and an intuitive interface that allows natural language questions, and can be one of the most useful portals for users to access an organization’s knowledge base.
That is, if the foundation is solid.
Advanced technology is only one piece of the puzzle. Here at Factor, we see a lot of people calling us after they’ve failed to deploy these types of advanced technologies, despite having great developers. The lack of an information strategy—the foundation— is what’s holding them back.
Using taxonomies, artificial intelligence, and chatbots as framework, I’ll explain the importance of an information strategy in taxonomies and ontologies in order to make AI-powered chatbots function at top performance.
How Taxonomies Support Best AI Practices
There is a natural relationship between AI, chatbots, and taxonomies. Taxonomies are the foundational level of data organization:
“When information is structured and indexed in a taxonomy, users can find what they need by working down to more specific categories, up to a more inclusive topic, or sideways to related topics.”
What is good for the users is also good for the AI. Having structured data decreases time-to-value for many AI projects so that you can get the most out of your technology investment as quickly as possible.
Taxonomies, and their more complex relatives, ontologies, interact with, support, and drive artificial intelligence (AI) technologies in many ways. The automation and benefits that organizations realize from AI-powered chatbot applications are only as good or bad as the quality of the data used. The better the information is organized, the better the data quality, the better it is aligned to the business and end user goals, the easier it is for the AI to utilize the information. Incomplete, erroneous or biased data will adversely affect both the user experience and your brand.
If your dream end state is a well-functioning system that delivers the most relevant information to people (easier said than done) consider the relationship between taxonomies, chatbots and artificial intelligence.
Quick History on Taxonomies: Berrypicking Model
In 1989, Marcia Bates published her “berrypicking” model, which has since proved foundational to the work of information seeking problems.
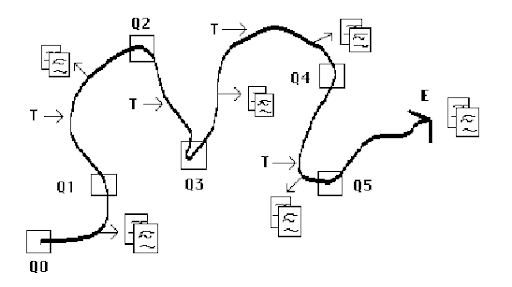
Copyright © 1989 by Marcia J. Bates
Bates described key elements of information-seeking behavior that provides a backdrop for parsing and converting an utterance to a query. This required a pretty large mindshift for developers. The ontology provides the capability to support this process, but the interface and interactions still need to be incorporated.
Bates discovered that:
- Typical search queries are not static, but rather evolve.
- Searchers commonly gather information in bits and pieces instead of in one grand best retrieved set.
- Searchers use a wide variety of search techniques which extend beyond those commonly associated with bibliographic databases.
- Searchers use a wide variety of sources other than bibliographic databases.
- Not only does a query get refined, but it may change significantly and move from one modality to another as the user’s understanding of the information evolves.
Practical Application and Implementation
The more things change… The more they stay the same
Factor recently worked with a large team of developers and AI engineers to build and implement new chatbots—taxonomists love working on projects from the ground up! We were interested to see how the project would differ from our standard Information Architecture projects. The Factor team has developed a long standing and methodical approach for e-commerce, portal, analytics, knowledge management and other similar projects. But an AI-based project was daunting. We were fully prepared to reassess our entire approach for chatbots but were surprised at how durable our methodology was!
Our approach takes a wide view of the information environment and we gather requirements accordingly. While this project required a deep dive into the technology and how it was being implemented, all other areas of our standard assessment approach were necessary as well. Understanding the user needs, the available content, legal and security issues, and the business goals of the chatbot were all essential inputs to the ontology model we developed.
What we determined was that an AI chatbot is really just another system; another set of requirements that fit nicely into our approach.
5 Things That Every Chatbot Should Consider
- Synonyms, homonyms, antonyms, etc.
- Query disambiguation
- Query expansion / refinement
- Identify relationships across domains
- AI training and rules, entity extraction
With the above core capabilities in mind, we entered the assessment phase to help us determine the necessary domains, the role of variants, relationships, the need for the ontology to interact with the content, etc. As a result of our assessment we were able to gather and provide requirements to the team that would design and build the chatbot. Each of the requirement areas below (in bold) had a direct impact on the overall ontology model.
Requirements Gathering
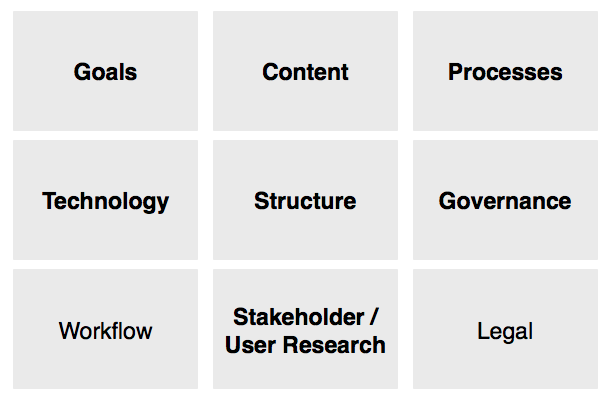
Taxonomy Construction Inputs
After the assessment, we turned to focus on what kind of sources the chatbot would require. An enterprise taxonomy project has many components, including governance, maintenance, system integrations, etc. For query focused projects like a chatbot, there are a number of sources that can be used, including:
- Entity extraction results from online and documentation content
- Review of search logs
- User questions documented by the support team
- Industry standard taxonomies and terminology
- Publicly available support documentation
- User research
- Ontology tool training and documentation
Sourcing the Taxonomy
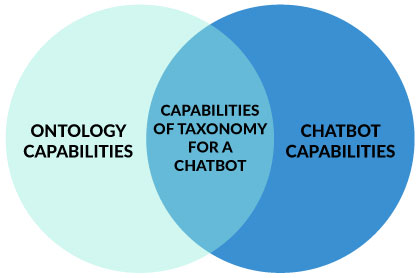
There are so many capabilities for a chatbot, but we focused on those that could be supported with taxonomies/ontologies. Once we put chatbot and ontology capabilities lists side by side, it was clear that chatbot capabilities are common across almost all findability projects. Realizing this has helped encourage us to stick to the basics.

Capabilities of Taxonomy for a Chatbot
- Synonyms, homonyms, antonyms, etc.
- Query disambiguation (I.e., “Turkey” the animal vs. “Turkey” the country)
- Query expansion / refinement (i.e., “Terrier” → Dog)
- Identify relationships across domains (i.e., Dog → Therapeutic Aids)
- AI training and rules, entity extraction
Factor has the opportunity to work with teams of extremely smart and information-centric engineers, which made the artificial intelligence component a little less daunting. We didn’t have to work very hard to convince people of the value of different types of entry terms (synonyms, antonyms, nicknames, etc). When the developers wrestle with the best way to interact with verbs, we are able to build them a “verb” taxonomy.
Below you can see where the capabilities (in yellow) that have dependence on the ontology.
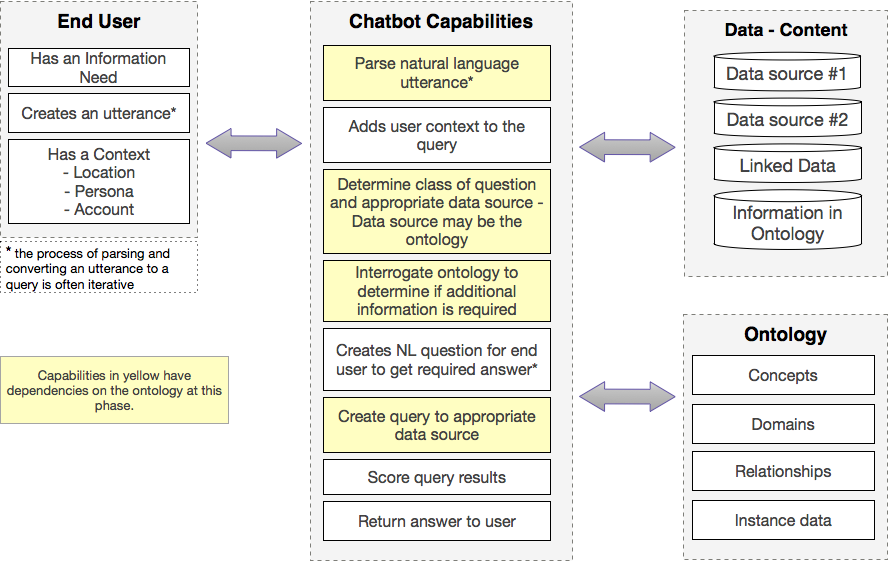
Final Thoughts
At a macro level, it’s estimated that poor data quality practices cost the US industry trillions of dollars per year and many millions for the average organization. Poor practices can slow down digital initiatives, frustrate employees, and potentially drive customers to competitor sites that are better able to meet their needs. To avoid all that gloom and doom remember the below points.
- Always consider the end user goals. The ontology we built was directly impacted by the content domain and content structure. By keeping end user goals as our north star, we were able to design the foundational taxonomy to meet the different chatbot capabilities across the technology, content, business goals, and resources going forward.
- Consider the AI-powered search infrastructure as a multipurpose tool. Not only does smart search leverage knowledge across the enterprise data silos and knowledge sources, it also employs advanced AI, NLP and deep learning to decrease time-to-value for AI-powered chatbots that serve employees, customers, support agents, and more.
- Invest in a robust information architecture. Don’t rely exclusively on AI, deep learning and NLP for your projects. Great taxonomy and information architecture work is critical for the best results. It takes great information architecture design with a strong governance methodology to ensure the high quality of data needed to power great AI projects, like smart chatbots.
- Trust the process. Factor’s standard process and assessment for the ontology/taxonomy design is remarkably durable. AI-powered chatbots may seem daunting, but treating the assessment process like any other taxonomy project helped us define and solve the problem on a fundamental level and work with developers and engineers to address findability and user satisfaction.
